Entrez Direct(EDirect)提供从UNIX终端窗口访问NCBI的互连数据库套件(发布,序列,结构,基因,变异,表达等)。函数从命令行参数中获取搜索项。将各个操作组合在一起以构建多步查询。记录检索和格式化通常会完成整个过程。
EDirect还包括一个参数驱动函数,它简化了从文档摘要或结构化XML格式返回的其他结果中提取数据的过程。这可以消除编写自定义软件以回答临时问题的需要。查询可以在EDirect命令和UNIX实用程序或脚本之间无缝移动,以执行无法在Entrez中完全完成的操作。
测试平台
MacMini 2.6 GHz Intel Core i5,macOS Mojave 10.14.2
安装
进入工作文件夹
创建src文件夹
进入src文件夹
下载edirect
解压缩
进入edirect文件夹并查看
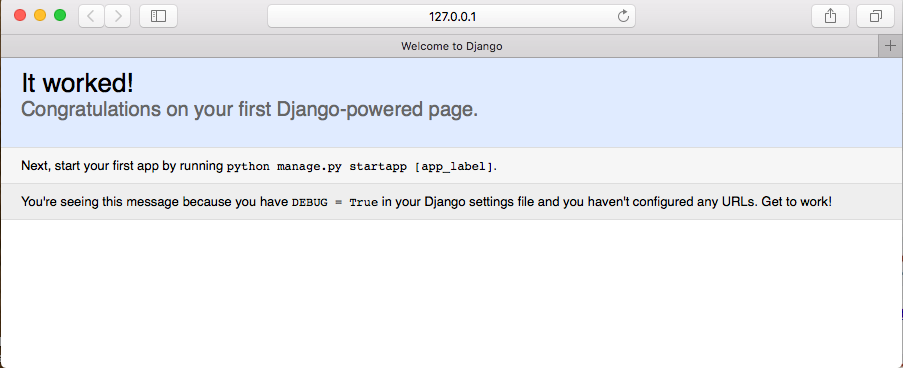
你可能已经发现setup,没错,这个就是安装文件
稍(喝)等(杯)片(茶)刻(吧),当看到输出
|
|
恭喜安装成功!
配置环境变量
把上面打印出来的 echo “export PATH=\${PATH}:/Users/adu/work/src/edirect” >> $HOME/.bash_profile 放到终端中,并回车已告诉系统EDirect的安装位置。注意每个人的安装路径都不一样,不要复制这里的应该复制你终端打印出来的。
|
|
如果出现 -bash: esearch: command not found 说明环境变量没有配置正确。
看到 esearch 11.1,说明可以愉快的使用 eDirect了
Entrez Direct 函数
导航功能支持Entrez数据库中的探索:
- esearch使用索引字段中的术语执行新的Entrez搜索。
- elink查找邻居(在数据库中)或链接(在数据库之间)。
- efilter过滤或限制先前查询的结果。
可以指定格式或文档摘要检索记录:
- efetch以指定格式下载记录或报告。
无需编写程序即可提取XML结果中的所需字段:
- xtract将EDirect XML输出转换为数据值表。
还提供了几个附加功能:
- einfo获取Entrez数据库中索引字段的信息。
- epost上传唯一标识符(UID)或序列登录号。
- nquire向网页或CGI服务发送URL请求。
esearch语法
|
|
databaseName(required)
数据库名字。指定数据库里查询
queryString(required)
查询关键字。在所在的数据库里查询的关键字
例子
在pubmed数据库中查询 “opsin gene conversion”
#######构建多步查询
edirect允许单独执行各个操作,通过使用竖线(“|”)Unix管道符号将它们组合成一个多步骤查询。从esearch到elink:
将查找初始结果的相关文章(预先计算的PubMed邻居)。
#######在多行上写入命令
通过在按回车键之前立即键入反斜杠(“\”)unix转义符,可以在下一行继续查询。继续查询链接到相关文章中发布的所有蛋白质序列:
垂直条管道符号还允许在下一行继续查询。
#######检索PubMed报告
通过管道将pubmed查询结果传送到efetch并指定“abstract”格式:
使用efetch格式的“medline”可生成一份报告,该报告可输入通用书目管理软件包中:
#######检索序列报告
核苷酸和蛋白质记录可以用fasta格式下载:
其他FASTA格式的变体是fasta-cds-na、fasta-cds-aa和gene-fasta
序列记录也可以以genbank(-format gb)或genpept(-format gp)格式文件获得,这些文件具有注释序列特定区域的功能:
搜索和筛选
####### 限制查询结果
目前的结果可以通过Entrez中的进一步术语搜索来改进(在蛋白质数据库中用于将BLAST邻居限制为分类子集):
结果也可以按时间过滤。例如,以下语句:
|
|
将结果分别限制在前两个月或1990年代发表的文章中。
####### 索引字段的合格查询
可以通过在括号中输入索引字段缩写来限定esearch或efilter中的查询字词。布尔运算符和括号也可以在查询表达式中用于更复杂的搜索。
PubMed查询的常用字段包括:
| Item | Value |
|---|---|
| [AFFL] | Affiliation |
| [ALL] | All Fields |
| [AUTH] | Author |
| [FAUT] | Author - First |
| [LAUT] | Author - Last |
| [PDAT] | Date - Publication |
| [FILT] | Filter |
| [JOUR] | Journal |
| [LANG] | Language |
| [MAJR] | MeSH Major Topic |
| [SUBH] | MeSH Subheading |
| [MESH] | MeSH Terms |
| [PTYP] | Publication Type |
| [WORD] | Text Word |
| [TITL] | Title |
| [TIAB] | Title/Abstract |
| [UID] | UID |
一个合格的查询看起来像:
结果如下
将搜索结果限制为PubMed子集的过滤器包括:
| Item | Value |
|---|---|
| humans | [MESH] |
| pharmacokinetics | [MESH] |
| chemically induced | [SUBH] |
| all child | [FILT] |
| english | [FILT] |
| freetext | [FILT] |
| has abstract | [FILT] |
| historical article | [FILT] |
| randomized controlled trial | [FILT] |
| clinical trial, phase ii | [PTYP] |
| review | [PTYP] |
序列数据库使用一组不同的搜索字段编制索引,包括:
| Item | Value |
|---|---|
| [ACCN] | Accession |
| [ALL] | All Fields |
| [AUTH] | Author |
| [GPRJ] | BioProject |
| [ECNO] | EC/RN Number |
| [FKEY] | Feature key |
| [FILT] | Filter |
| [GENE] | Gene Name |
| [JOUR] | Journal |
| [KYWD] | Keyword |
| [MLWT] | Molecular Weight |
| [ORGN] | Organism |
| [PACC] | Primary Accession |
| [PROP] | Properties |
| [PROT] | Protein Name |
| [SQID] | SeqID String |
| [SLEN] | Sequence Length |
| [SUBS] | Substance Name |
| [WORD] | Text Word |
| [TITL] | Title |
| [UID] | UID |
并且蛋白质数据库中的样本查询是:
结果如下
序列数据库中子集过滤器的其他示例如下:
| Item | Value |
|---|---|
| mammalia | [ORGN] |
| mammalia | [ORGN:noexp] |
| cds | [FKEY] |
| lacz | [GENE] |
| beta galactosidase | [PROT] |
| protein snp | [FILT] |
| reviewed | [FILT] |
| country united kingdom glasgow | [TEXT] |
| biomol genomic | [PROP] |
| dbxref flybase | [PROP] |
| gbdiv phg | [PROP] |
| phylogenetic study | [PROP] |
| sequence from mitochondrion | [PROP] |
| src cultivar | [PROP] |
| srcdb refseq validated | [PROP] |
| 150:200 | [SLEN] |
(计算的分子量(MLWT)字段仅针对蛋白质(和结构)而非核苷酸编制索引。)
####### 检查中间结果
EDirect将中间结果存储在Entrez历史服务器上。 EDirect导航功能生成一个自定义XML消息,其中包含相关字段(数据库,Web环境,查询键和记录计数),可以读取管道中的下一个命令。
在添加下一步骤之前,可以检查查询中每个步骤的结果以确认预期的行为。 ENTREZ_DIRECT对象中的Count字段包含上一步返回的记录数。查询成功的一个很好的衡量标准是合理的(非零)计数值。例如:
结果如下:
在指定的分子量范围内具有39个蛋白质结构并具有所需的(X射线晶体学)原子位置分辨率。
(QueryKey值为7而不是5,因为每个elink命令通过在ELink操作之后立即运行单独的ESearch查询来获取记录计数。)
####### 结合独立查询
可以执行独立的esearch,elink和efilter操作,然后使用历史服务器的“#”约定来表示查询键号。 (要组合的步骤必须位于同一个数据库中。)后续的esearch命令可以使用-db参数覆盖上一步中传送的数据库。 (将查询连接在一起对于共享相同的历史记录线程是必要的。)例如,查询:
|
|
使用截断搜索(输入单词的开头后跟星号)返回与淀粉样蛋白序列和载脂蛋白基因记录相关的论文标题:
|
|
使用(#3)AND(#6)代替上面的(#2)AND(#4)反映了每个elink命令执行单独的ESearch查询的需要,该查询增加QueryKey,以获得记录计数。 -label参数可用于绕过此工件。标签值以“#”符号为前缀,并放在最终搜索的括号中。从而:
|
|
将返回:
无需跟踪内部QueryKey值。